


PRS模型-预测复杂疾病风险的机遇与挑战
- boke
- 2022-05-23
- 9:00 下午
PRS是基于遗传数据预测复杂性状,随着研究人员展示其在改善临床护理方面的多种应用,对各种表型的基因研究在规模和能力上都有所增加,随着基因检测成本大幅下降,医学对PRS应用的兴趣日益浓厚。许多早期对预测能力有限的批评现在被认为主要是样本量不足的问题,目前这种情况已经得到改善。例如,在欧洲血统的个体中,PRS已经比目前的临床模型更准确地预测乳腺癌、前列腺癌和1型糖尿病的风险。此外,PRS与其他生活方式和临床因素的集成模型使临床医生能够更准确地量化患者心脏病发作的风险;因此,他们通过给心血管疾病总体风险最高的患者开他汀类药物,更有针对性降低低密度脂蛋白胆固醇。虽然我们都对PRS作为临床生物标记来改善健康管理的潜力抱有极大希望,但目前普遍认为它们对欧洲血统的人群比其他血统人群的预测准确度更高,这是临床实践的主要挑战和瓶颈之一。
在以往的研究中发现:PRS在欧洲人群中预测个体风险比在其他族群中预测更准确。迄今为止的人群队列研究在全球范围内严重低估了非欧裔血统人群的代表性。真实的表型和基因预测的表型之间的相关性随着遗传差异的减少而减弱;因此,不同群体中多基因得分的准确性高度依赖于现有研究群体在GWAS“训练集合”中的代表性。截至2018年,大多数全基因组关联研究(GWAS)都是在欧洲(52%)或亚洲(21%)人群中进行的,这些研究旨在确定与疾病风险等复杂性状相关的遗传变异(图1)。当考虑到基于种族的GWAS所包含的个体数量时,78%是欧洲人,10%是亚洲人,2%是非洲人,1%是西班牙人,而所有其他种族在GWAS中占比<1%(图1)。
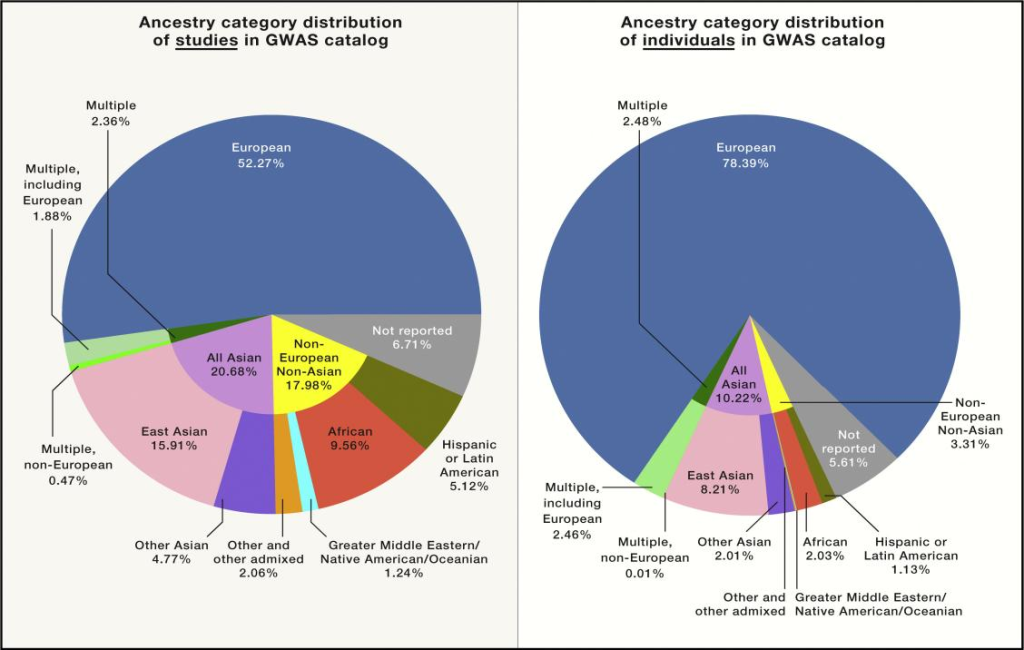
图1 截至2019年1月,GWAS研究按族群分类的汇总统计
跨人群遗传研究结果的通用性差的原因是欧裔血统人群研究占有压倒性优势以及其他不同的族裔缺乏基础研究的数据。根据GWAS的分类统计,尽管只占全球人口的16%,但约79%的GWAS参与者是欧洲人后裔(图1)。这种人群不平衡尤其明显,因为以往的研究表明,与欧洲类似规模的研究相比,对西班牙裔/拉丁裔个人和非裔美国人的研究贡献了过多的关联。自2014年底以来,非欧洲人在GWAS中的比例一直停滞不前或下降(图2),因此表明缺乏纠正这种不平衡的轨迹。这些数字提供了研究可获得性和使用的综合衡量标准–已被纳入众多GWAS的队列多次出现,欧洲血统的队列可能被过量地纳入研究。然而,尽管欧洲人的GWAS平均样本量继续增长,但其他血统人群的平均样本量却增长缓慢。
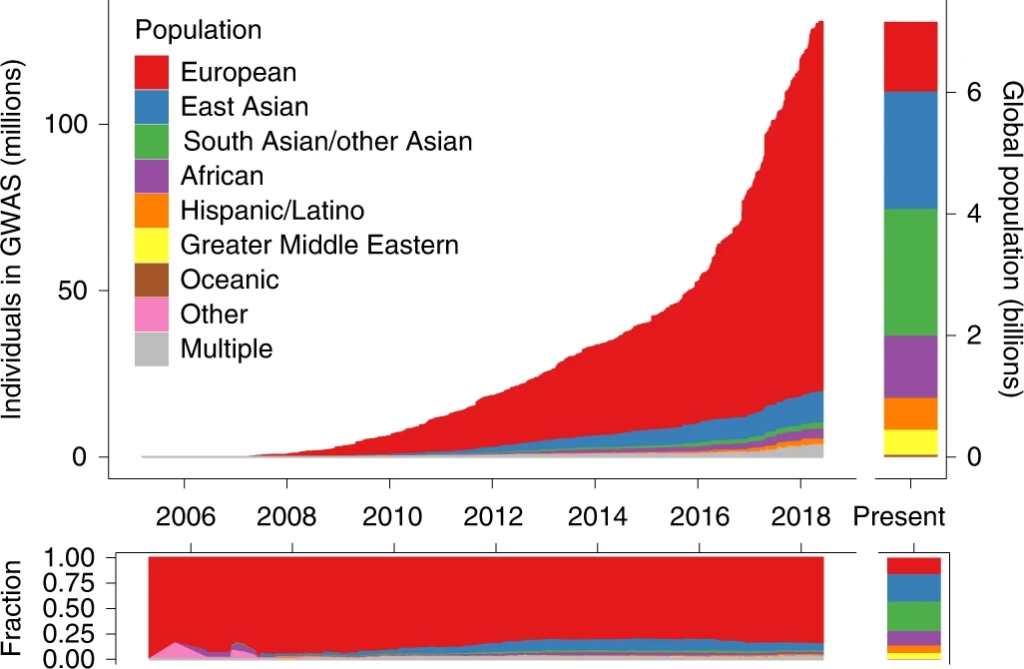
图2 与全球人群相比,GWAS 参与者各血统比例的历年变化情况
在基因研究中发现关联的能力取决于效应的大小和变异的频率。由于这种依赖,最重要的关联往往在发现它们的人群中比在其他地方更常见。例如,平均而言,GWAS变异在欧洲人群中比在东亚和非洲群体中更常见(图3b),这一观察结果不能代表整个基因组变异。研究不足的群体为基因发现提供了丰富的素材,因为即使是非常大的欧洲样本量,也无法发现在这些群体中常见但在欧洲群体中很少或没有的变异。一些例子包括拉丁裔人群中SLC16A11和HNF1A与2型糖尿病的关联,以及APOL1与终末期肾病的关联以及非洲裔人群中与前列腺癌的关联。如果假设遗传变异在所有人群中都有相同的影响–这一假设得到了一些经验支持,为可转移性提供了最好的情况。以欧洲为中心的GWAS数据偏向将导致风险相关变异在欧洲人群中过高估计,因此在欧洲人群中占表型差异的更大比例。此外,基因型填充数据集与GWAS中的研究偏向相同,因此为缺失型填充带来了挑战,这些位点在欧洲人群中很少见,但在其他地方很常见,因为非欧洲单倍型的数据量要小得多。
连锁不平衡。由于历史的原因,基因组的相关结构LD在不同的人类族群中是不同的。这些LD的差异反过来又推动了不同群体间GWAS的效应大小估计(即预测因子)与标记SNP和因果SNP对之间的LD的比例的差异,即使因果效应是相同的)。由于LD差异而导致的效应大小估计的差异对于基因组的大多数区域来说通常是很小的(图3c-e),但PRS总和跨越了这些影响,也聚集了这些群体差异。虽然理想情况下使用因果效应而不是相关的效应大小估计来计算变异系数,但将大多数变异精确地映射到一个位点来解决推广能力低的问题可能是不可行的,即使是在非常大的GWAS情况下也是如此。这种不可行性是因为复杂的性状是高度多基因的,因此大多数预测能力来自不符合全基因组意义和/或不能被精细定位的小效应,即使在许多迄今最强大的GWAS队列数据中也是如此。
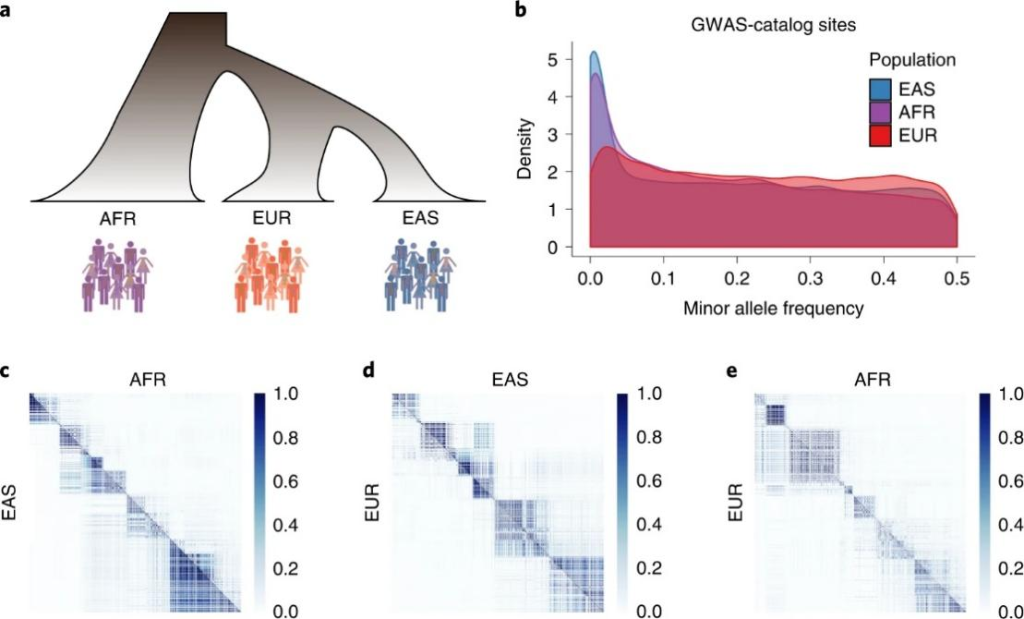
图3 人类族群的谱系演化关系、等位基因频率差异和局部LD模式
历史、选择和环境的复杂性。最后,其他队列考虑因素可能会以更难预测的方式进一步恶化不同人群之间的预测准确性差异。不同群体间的GWAS和LD差异的解决是极具挑战性的,但人们可以假设所有关联基因座在所有群体中都具有相同的效果,并面临同等的选择压力。相比之下,对多基因适应或风险得分的其他影响,例如全球人口之间长期存在的环境差异,导致对自然选择的不同反应,可能会对人口产生不同的影响,这取决于他们独特的历史。此外,未纠正的剩余人口分层可能会影响整个人口的风险预测准确性,但其影响的程度目前尚不清楚。这些影响尤其具有挑战性,这在身高方面已经得到了明确的证明,多基因适应的证据和/或其相对大小受到质疑。遗传背景高度不同的群体在地理上分层的表型(如身高)的比较造成了环境差异,如各大洲发展过程中资源的差异,特别容易与相关的环境和遗传差异混淆。这种残余分层可能会导致整个地理空间的过度预测差异。
环境暴露、基因-基因相互作用、基因-环境相互作用、群体历史动态、统计噪声、一些潜在的因果效应差异和/或其他因素的差异以不可预测的、特定于特征的方式进一步限制了PRS的通用性。复杂的性状并不以遗传决定的方式表现:一些环境因素使个体的遗传效应相形见绌,从而产生了全球不同群体之间可比性的巨大问题。例如,在精神障碍中,精神分裂症在东亚人和欧洲人中具有几乎相同的遗传基础,而不同人群的酒精代谢率有很大差异,部分原因是可获得性差异和影响酒精代谢的遗传差异。除了纯加性模型外,非线性遗传因素对复杂性状的解释很少,但一些未被识别的非线性和基因-基因交互作用也会对遗传风险预测带来挑战,因为成对交互作用可能在不同群体之间比单个SNPs变化更大。在数学上,这种情况可以简化地用两个SNP模型来考虑,其中两个SNP效应的总和可能比相同SNP的乘积解释更多的表型差异。因此,一些机器学习方法可能会比目前针对某些表型的方法略微提高PRS的准确性,但最简便的改进是具有更简单的结构、已知的相互作用和较差的跨群体通用性的非典型特征,如皮肤色素沉着。
迄今为止,由于在不同人群中的可推广性有限,多祖先研究在大多数疾病地区进展缓慢,因此甚至限制了在非欧洲队列中评估疾病的应用。尽管如此,以前的一些工作已经评估了不同人群在几个特征和疾病方面的预测准确性,这些特征和疾病可以获得GWAS的汇总统计数据,并发现了不同人群之间的巨大差异。这些差异不仅仅是方法论问题,因为不同的方法和精度指标表明,在一系列多基因性状在不同群体中预测准确性存在差异。随着全球生物库的增长和数据开放,这些评估正变得越来越可行。我们评估了英国生物库(UKBB)在使用来自欧洲的统计数据时发现,全球不同人群中17个人体和血液检测指标的PRS预测准确性是有差异的。这与之前的研究结果一致,我们发现其他人群的基因预测准确率远远低于欧洲人群:平均来看,西班牙裔/拉美裔美国人低1.6倍,南亚人低1.6倍,东亚人低2.0倍,非洲人低4.5倍(图4)。
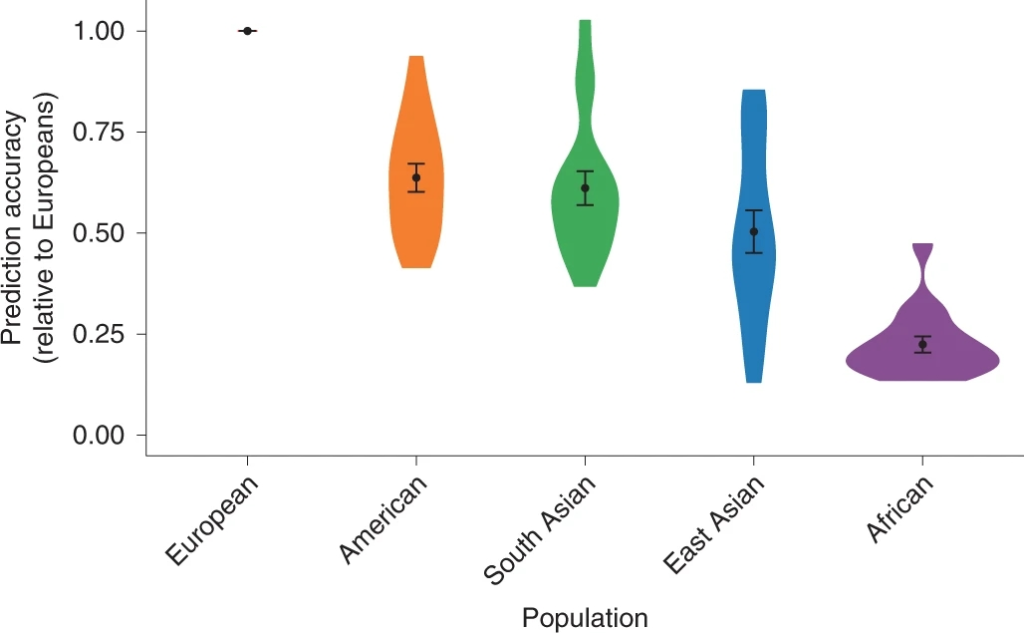
图4 UKBB中17个数量性状和5个大陆人群相对于欧洲血统个体的预测精度
尽管已经在多祖先环境中研究了许多其他特征和疾病,但很少有研究报告跨种群预测准确性的指标。例如,心血管疾病PRS研究引领了多基因风险评估的临床应用。这是由于冠状动脉疾病增加的SNPs的多基因变异可以带来单基因等值的心血管疾病风险,而PRS改善了风险评估的临床模型和他汀类药物处方,可以减少冠心病并提高治疗的效率。然而,这些研究中有许多只在欧洲裔人群中进行,很少有研究严格评估人群水平对非欧洲人的适用性。这些发现确实表明,非欧洲人群的预测效用大幅下降,这使得跨族裔人群研究的比较具有挑战性。为了更好地阐明如何在具有不同群体的临床环境中应用多基因预测,仍需要对许多复杂性状的群体内和群体间PRS的效用进行更系统和彻底的评估。这些评估将受益于对多基因预测准确性的严格评估,特别是对不同族裔的患者。
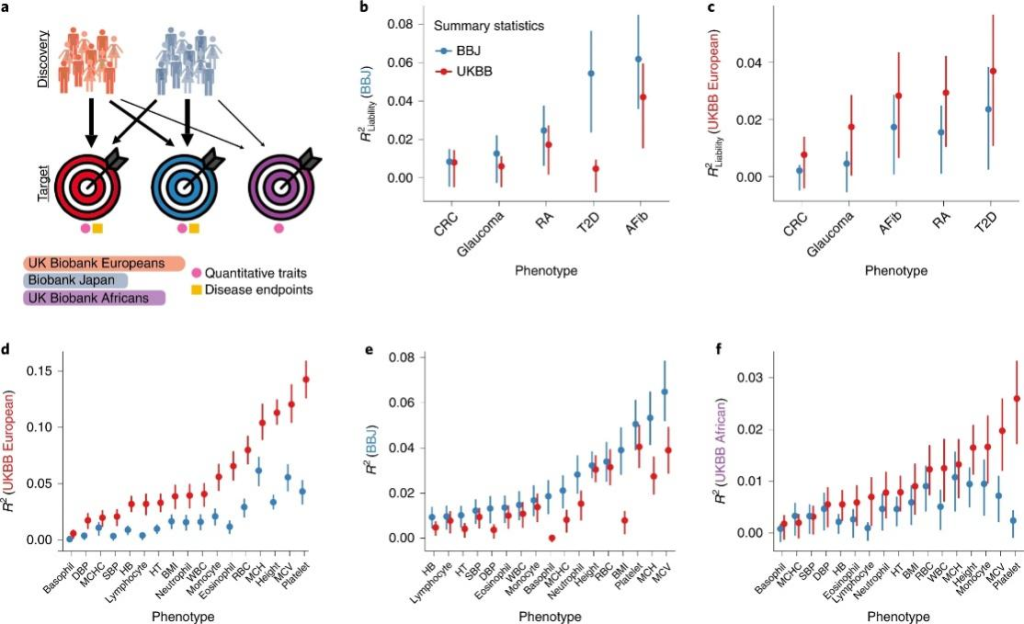
图5 在BBJ和UKBB中使用相同样本量的独立GWAS分析的基础上,日本人、英国人和非洲人后裔的多基因风险预测准确性比较
图6 PRS模型开发和验证整体流程
那么怎么才能做好PRS模型的开发呢?2021年《Nature》杂志上发表了一篇题为“Improving reporting standards for polygenic scores in risk prediction studies”的综述,该综述提出一个框架确定了科学家在其研究中应该包含的与PRS多基因风险评分相关的最低限度信息。该框架由国家人类基因组研究所(NHGRI)的临床基因组资源(ClinGen)复杂疾病工作组和多基因评分(PGS)目录数据库成员创建,将有助于提高多基因风险评分的有效性、透明度和可重复性。PRS风险模型的建模数据集和验证数据集中均需要充分考虑非遗传变量(例如年龄、性别、族群信息、临床变量等等)。通过拟合程序选择最佳风险模型并在独立样本中验证该模型的有效性。它适用于PRS开发和验证研究,旨在预测疾病发生和预后,以及对治疗的反应。大多数PRS研究遵循PRS开发评估的原型流程(图6),该流程可作为标准化报告和实际应用的模板。这些项目涵盖了研究人类族群的详细背景信息,开发和验证PRS的统计方法以及局限性的充分考量。


